



Design a Coding Contest Platform like Leetcode
Remote code execution engine and database design.

This system needs to efficiently manage and deliver coding problems with low latency, handle concurrent user submissions, provide real-time leaderboard ranking, and be responsive during the coding contests.
These are the components we’ll cover today:
Delivery of the static content like prompts and submission results.
Storing static files in the object storage
Replicate across CDN for low latency
Maintain a problem metadata database
Remote code execution engine
Queue-based async submission process
Isolated execution environment
Autoscaling pool of task forkers based on the queue size
Real time contest leaderboard
MapReduce and streaming processing of the code submissions
In place leaderboard updates based on the streaming process
Historical leaderboard state snapshots based on the heavier map reduce jobs

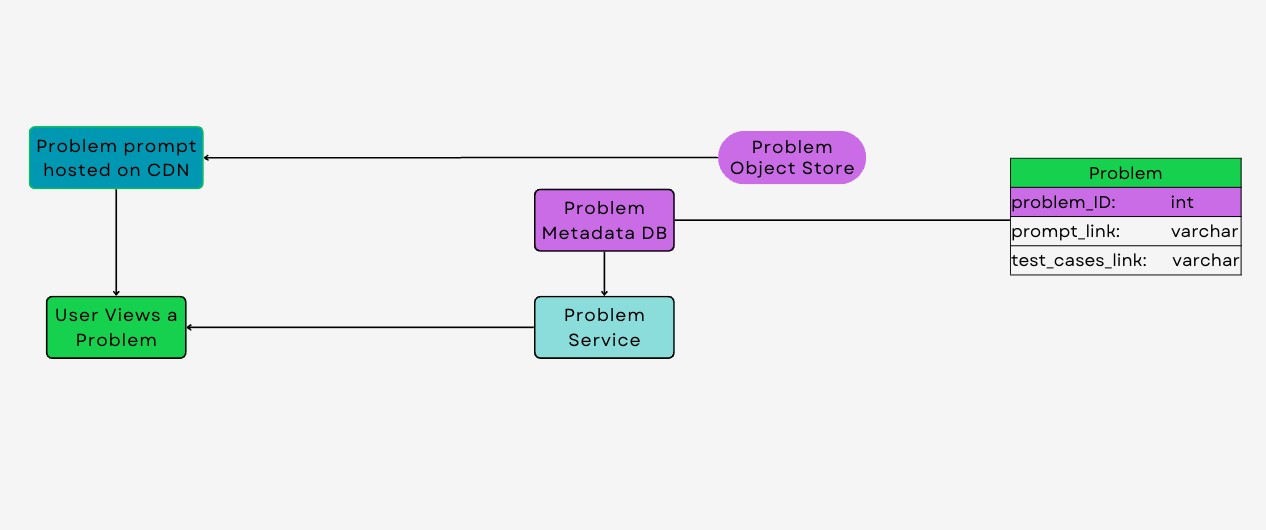
Problem Object Store and CDN
The core of the coding contest platform is its repository of coding problems, which are stored as static text files in an problem object store like S3. Each problem file contains the problem statement, example inputs and outputs, constraints, and any other relevant information that the user needs to understand the problem.
To ensure that these problem statements are delivered quickly and reliably to users across the globe, the system integrates with a Content Delivery Network (CDN). A CDN is a network of distributed servers that deliver content to users based on their geographic location. When a user accesses a coding problem, the CDN routes the request to the nearest server, which then delivers the problem statement. This approach significantly reduces latency and improves the user experience, especially in a platform where response times are critical.
Code Execution Engine
Responsible for storing, compiling, and executing user-submitted code. This engine must be secure, scalable, and support multiple programming languages. It typically operates in an isolated and auto-scaling environment, such as pool of Docker containers, to ensure that code execution is sandboxed, preventing any potential security risks.

When a user submits a solution it follows the following workflow:
1. Submission Processor service
User submissions are first stored in a Submission Object Store like S3. It can manage the influx of user code, tagging each submission with unique metadata for easy retrieval and process.
2. Queue (Kafka)
Upon submission storage, a JSON message containing the submission and problem IDs is dispatched to Kafka. Kafka serves as a distributed messaging queue, enabling asynchronous processing and decoupling the submission intake from the execution phase.
3. Task Runners
Task Runners, consuming messages from Kafka, retrieve the user's code and the associated problem's test cases from the object storage. They execute the code in a scalable, secure, and isolated environment, supporting multiple programming languages. The Task Runners assess code against predefined test cases, focusing on correctness and performance metrics like execution time and memory usage.
4. Submission Object Storage
Post-execution, the Task Runners compile the results - correctness, performance metrics, and other relevant data - and store them in a metadata DB and object storage. These data will be used to render user’s progress in the profile and during the contest in the leaderboard.
Contest Leaderboard
The design of a coding contest leaderboard involves data extraction, processing, and storage to ensure real-time, accurate ranking of participants. This system typically reads data from a submission object store, processes it using Batch MapReduce and streaming processes, and then stores the processed data in a leaderboard database.

Data Extraction
The process begins with data extraction from the Submission Object Store. This store contains all user submissions, including code, execution results (like pass/fail status, execution time, and memory usage), and user identifiers. For leaderboard computation, key information such as submission time, problem ID, user ID, and execution success is crucial.
Data Processing
Once the data is extracted, the next step is processing it to compute rankings. This is where batch and streaming processes come into play.
MapReduce for Batch Processing: MapReduce is used for batch processing of submission data. In the Map phase, submissions are categorized and organized - for example, mapping each submission to its corresponding problem and user. In the Reduce phase, these mapped submissions are aggregated to compute metrics like total problems solved, average execution time, and success rate for each user.
Streaming for Real-Time Updates: In addition to batch processing, streaming processes are implemented for real-time leaderboard updates. These processes continuously monitor the submission object store for new data. As new submissions come in, they are instantly processed to update relevant metrics like recent problem solves or improvement in execution time.
Storing Data in the Leaderboard Database
After processing, the computed leaderboard data is stored in a 2 formats:
SQL database. This leaderboard database is optimized for fast read and write operations, given that leaderboard updates are frequent and users expect quick access to their standings. Indexes on user_id, contest_id, and rank can be applied to optimize query performance, ensuring that even complex queries, like filtering by contest or rank, are executed swiftly.
NoSQL historical database. This database is used for the fraud detection and other analytics that is performed after the contest. It stores contest state snapshots at the specific point in time. It allows to understand the dynamic of the contest, detect suspicious events, and collect additional on demand metrics.
Check out a concise video coverage on my Youtube.
📣 I enjoyed reading the week
How Cloudflare Was Able to Support 55 Million Requests per Second With Only 15 Postgres Clusters on
by - Technics to get the maximum out of your Postgres cluster.SDC#26 - Intro to Change Data Capture on
by Clear and concise post on Change Data Capture and Cache invalidation- by Practical tips on how to make meeting more efficient.
How to Build a Scalable Notification Service on Quastor by Arpan G Main challenges and solutions for scaling a Notification System.
Thank you for your continued support of my newsletter and the growth to a 5k+ members community 🙏
You can also hit the like ❤️ button at the bottom of this email or share this post with a friend. It really helps!










Very interesting content. Loved it. Keep up the great work 👍👍👍...
But how leetcode match the output of genterated file with output file testcase i mean they are using string pattern matching algo but how for the probelm statement which is saying you can return the output in any order??