



4 Essential Components to Design a Data Warehouse
Design a Columnar OLAP database.

Today, we’re going to design a scalable real-time distributed data warehouse optimized for data analytics and real-time applications. Its unique architecture, designed to serve high throughput and low latency queries. We will go deep into 4 core components of the design:
Routing service
Real-time servers
Offline servers
Distributed storage

Routing Service
The routing service plays a critical role in query processing. It acts as the brain of the system, determining how and where a query should be executed in the cluster. It’s responsible for analyzing incoming queries and routing them to the appropriate servers where the relevant data resides.

To achieve this, the routing service maintains a metadata directory of all segments and their locations within the cluster, ensuring that queries are directed to the nodes that contain the necessary data.
Routing service dynamically adapt to the cluster's state. It monitors the health and load of servers and can reroute queries to ensure optimal load balancing and fault tolerance. This aspect is crucial in maintaining high availability, especially in scenarios where the cluster faces node failures or sudden spikes in query load.
Real-time Servers
Real-time servers are designed to provide instantaneous data analytics. These servers ingest data in real-time, typically from streaming sources like Apache Kafka, and make it immediately available for querying. This capability is essential for applications requiring up-to-the-minute data, such as real-time dashboards, anomaly detection systems, and operational monitoring tools.

The real-time servers manage data in two primary forms:
They consume segments. Consuming segments are where the real-time ingestion happens, with data continuously appended as it arrives.
They complete segments. Once a consuming segment reaches a certain size or age, it's converted into a completed immutable segment that gets storage in a distributed storage.
This segmentation strategy is key to efficient data handling, allowing for optimized query performance on real-time data while ensuring data consistency and durability.
Offline Servers
While real-time servers handle the immediate data, offline servers are tasked with managing historical data. These servers store data that has been batch-processed, typically loaded from Hadoop, S3, or other batch data sources. Offline servers provide the ability to perform deep and complex analytics on historical data, complementing the insights gained from real-time data.
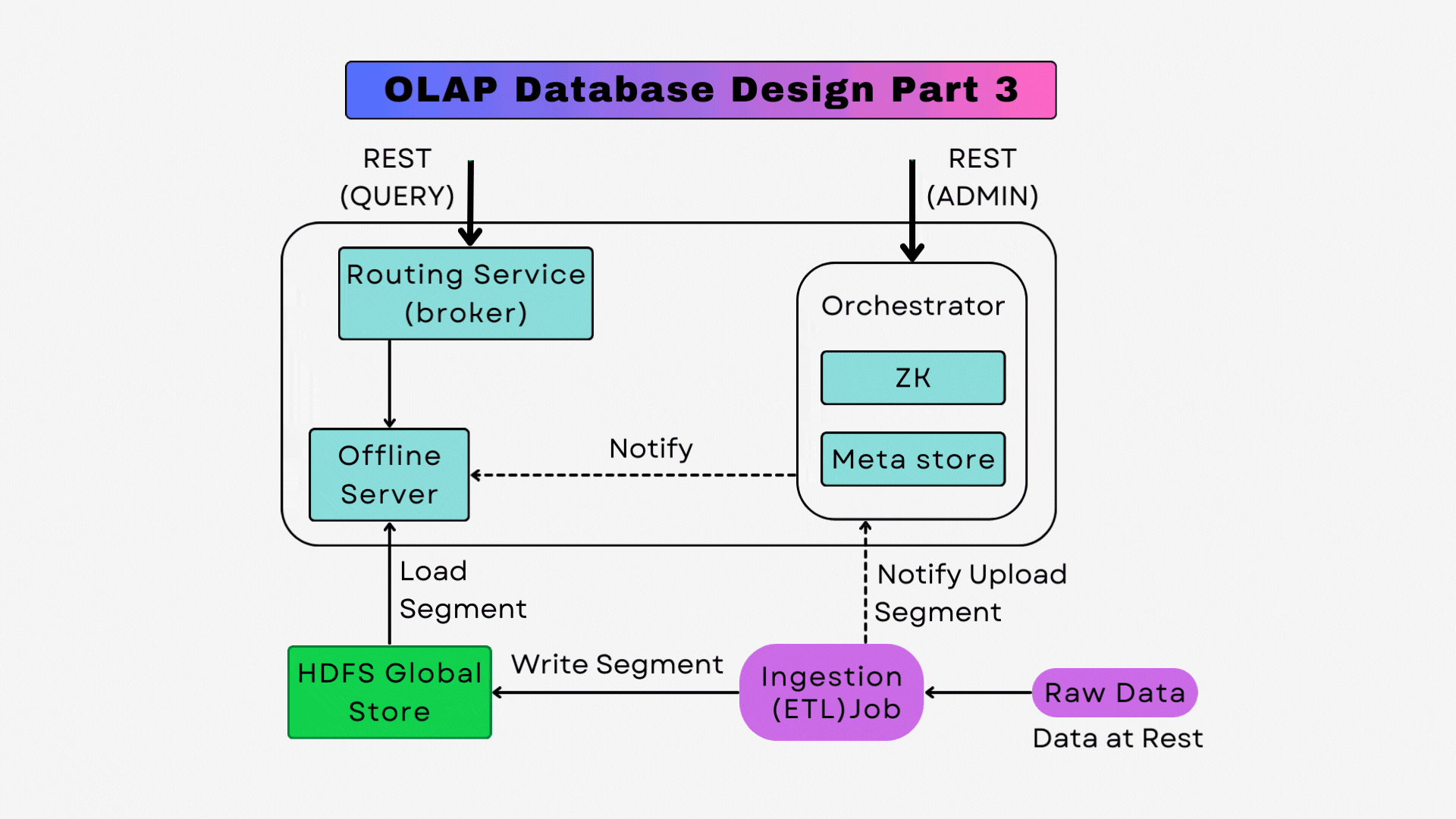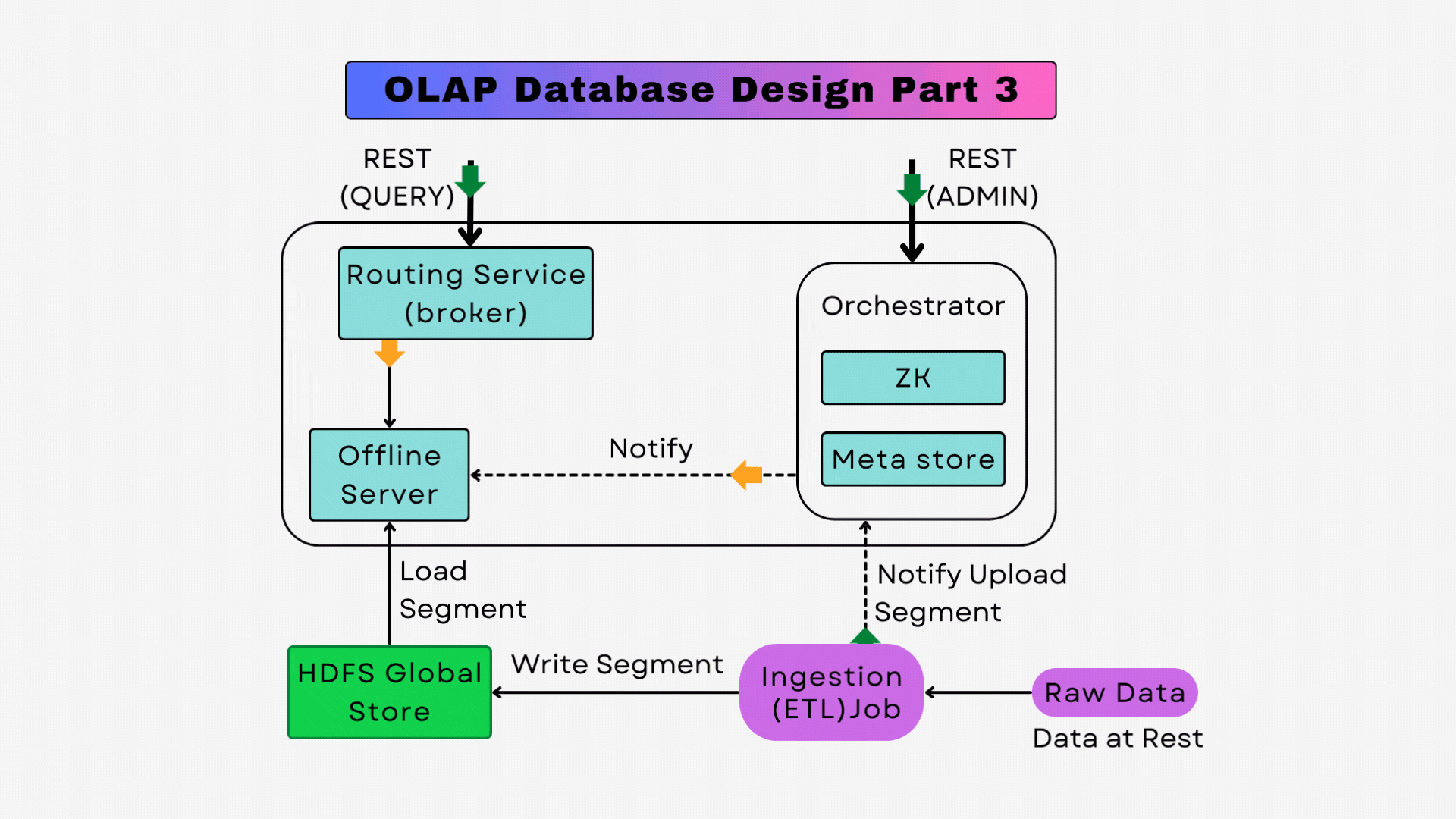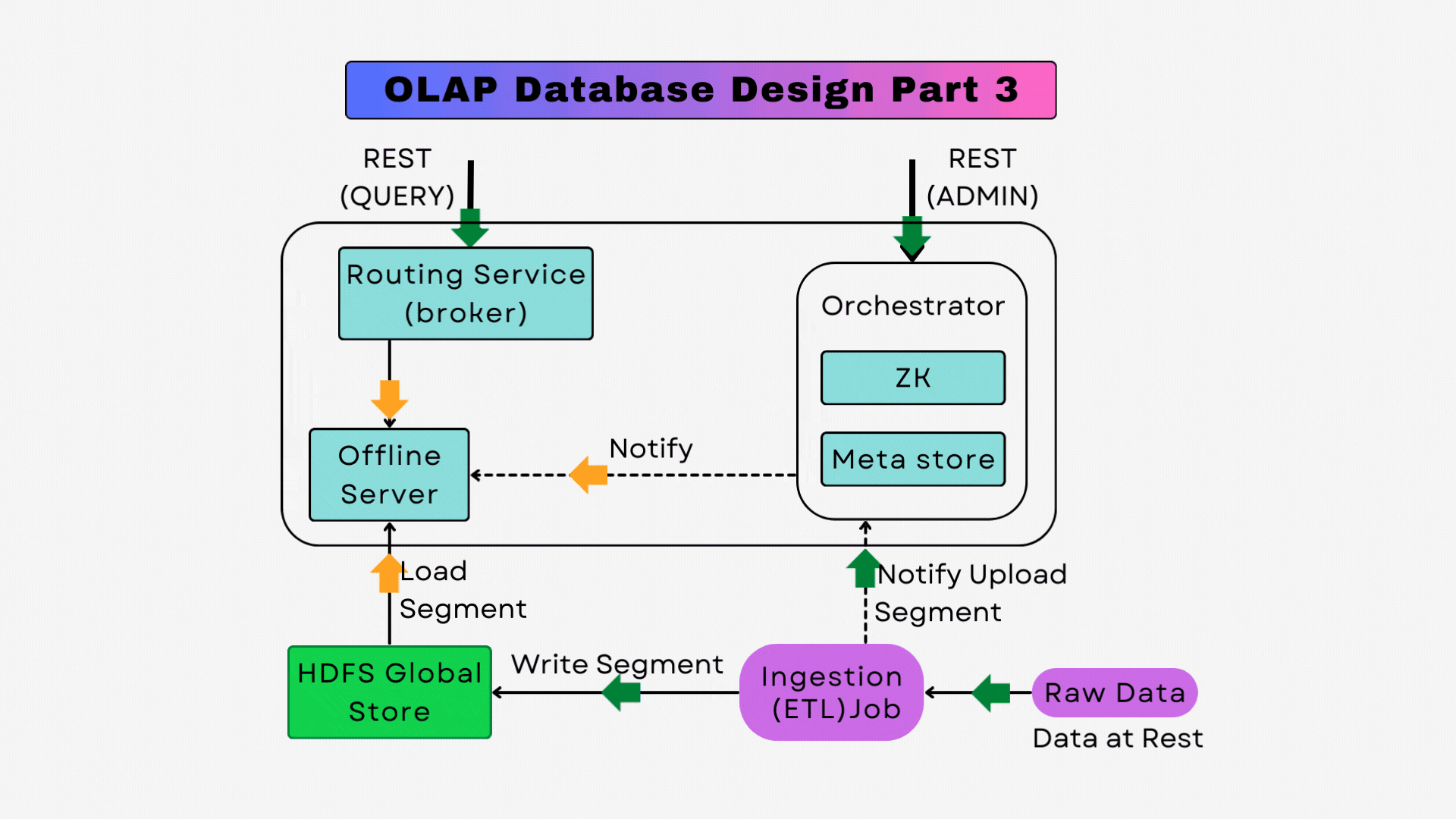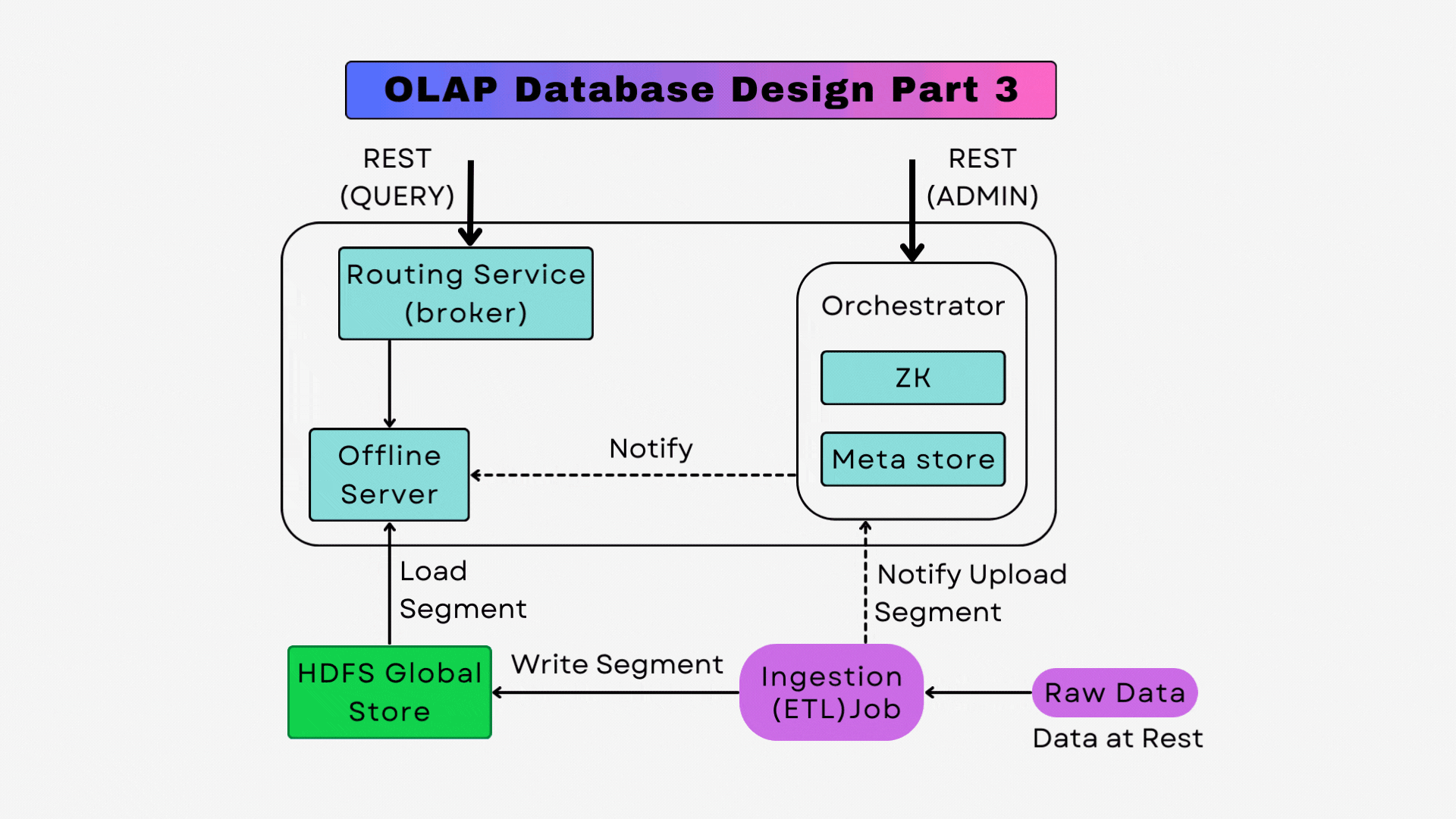
The offline servers store data in immutable segments, which are optimized for read-heavy workloads. This immutable nature ensures consistency and simplifies data management, as there's no need to handle concurrent writes and reads. To handle large datasets, we leverage distributed storage, with segments distributed and replicated across multiple nodes in the cluster. This distribution ensures both scalability and fault tolerance, as data is available even in the event of node failures.
Distributed Storage
The distributed storage architecture is a cornerstone of our design, enabling it to store and manage vast amounts of data efficiently. This system is built to scale horizontally, allowing for the addition of more nodes to the cluster to increase storage capacity and compute power. Data in is stored in segments, which are distributed and replicated across the cluster.
The distributed nature of storage also enables it to handle high query loads effectively. Queries are parallelized and executed across multiple nodes, leveraging the distributed compute resources. This parallel execution capability is key to achieving low-latency responses, even when dealing with large-scale datasets.
Query Engine
The querying engine spans across both real-time servers and offline historical storage. It’s a sophisticated process designed to deliver fast and efficient access to data, regardless of whether it is being streamed in real time or accessed from historical records.
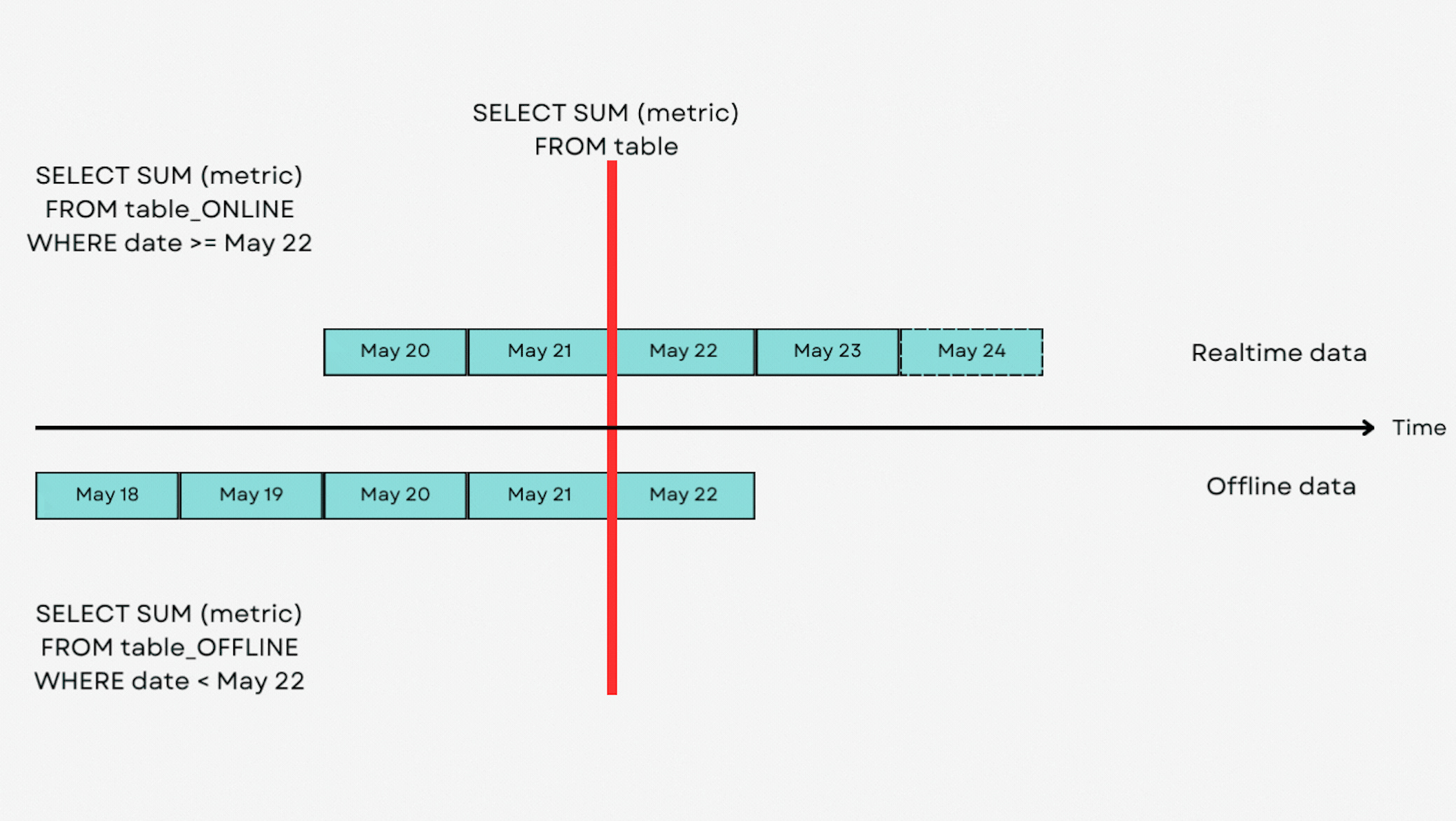
When a query is issued that involves real-time data, it is routed to the real-time servers holding the relevant consuming or completed segments. Real time data is retained for a short amount of time (weeks to months).
Queries on historical data are routed to the offline servers. Since the data is not changing as in the real-time servers, offline servers can optimize query execution differently, focusing on maximizing throughput and efficiency for large-scale data.
📣 Shout-outs of the week
- by - Great explanation of a Cell Based Architecture. Its a very common technique for a large scale design. Facebook F4 uses cell based design for the media blob storage and I made a video on it last year.
- by Fantastic article on the most common problem every engineer goes through. Delegation and scaling yourself.
Vague Feedback Blocking Promo? on
by Good reminder on how to handle vague feedback and feedback in general.
Thank you for your continued support of my newsletter and the growth to a 5k+ members community 🙏
You can also hit the like ❤️ button at the bottom of this email or share this post with a friend. It really helps!










