



Deep dive on a log-based queue (Kafka) design
Topics, partitions, file system cache and segment files. Reading from a specific offset or timestamp.

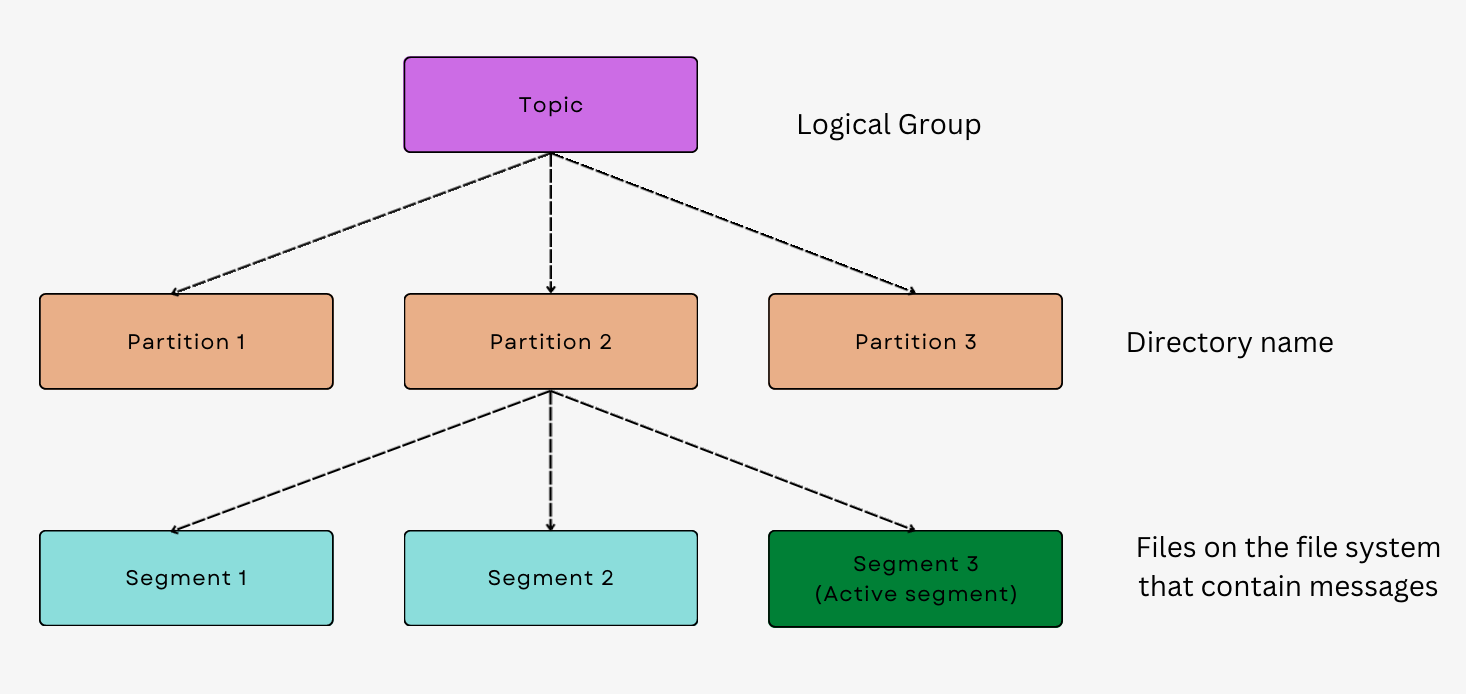
The storage design of Apache Kafka is based on topics and partitions. A topic is a named stream of records, and a partition is a subset of the data for a particular topic. Each partition is an ordered, immutable sequence of records that is continually appended to.
The data in each partition is replicated across multiple brokers, which are the nodes in the Kafka cluster. The replicas are stored in separate machines to ensure high availability and fault tolerance. In addition, Kafka uses a ZooKeeper ensemble to maintain metadata about topics, partitions, and their replicas.
Kafka uses a write-ahead log (WAL) to store records on disk. Each partition has a dedicated log that maintains a sequence of records. The WAL is stored on disk in a compressed format to save storage space. The records are not deleted from the WAL once they are written. Instead, the records are marked with a retention policy that specifies how long they should be kept.
Segment files are the underlying files that store the log data for each partition. When a new partition is created, Kafka starts with an empty segment file. As data is written to the partition, it is appended to the segment file. Once the segment file reaches a certain size, typically 1 GB, Kafka creates a new segment file and starts appending new data to it. This process continues as more data is written to the partition.
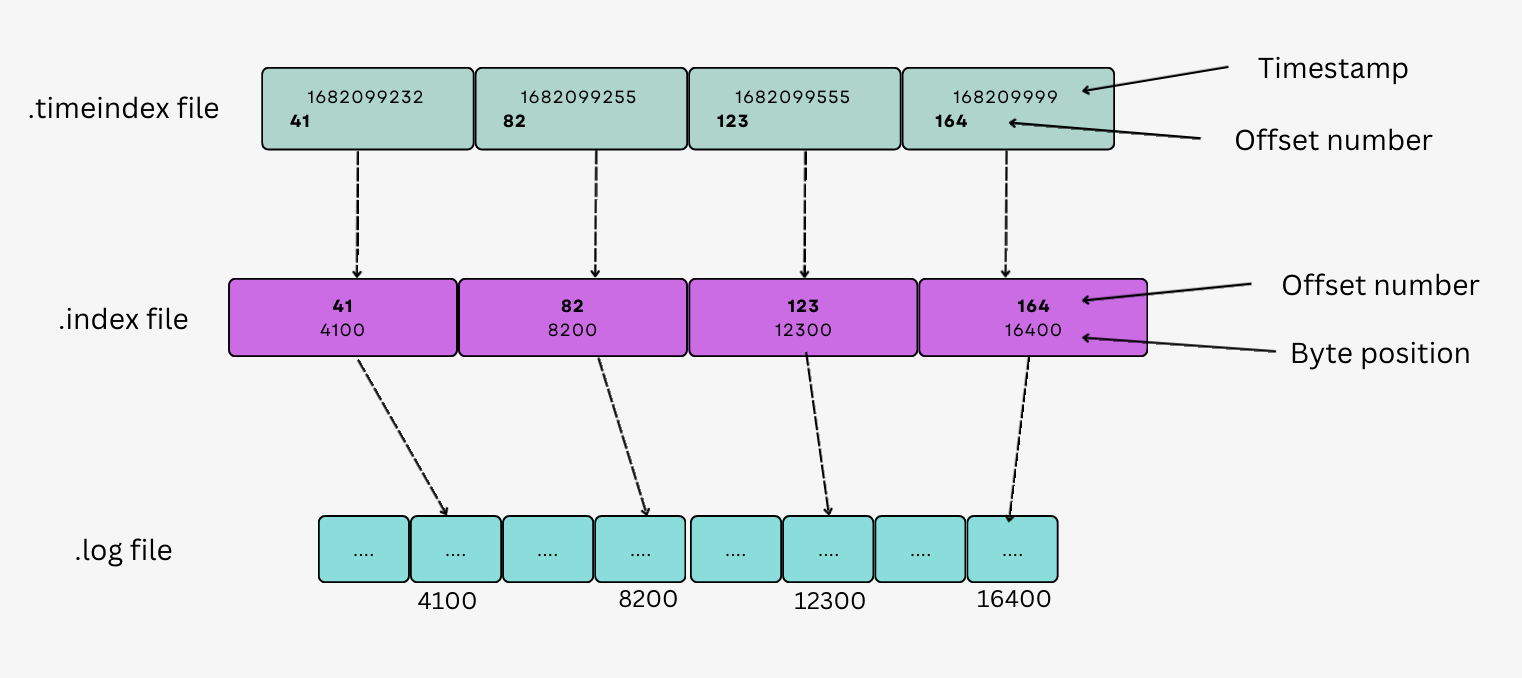
Each segment file is a self-contained file that contains a sequence of records in the order they were written. The records are stored in a binary format that includes a timestamp, key, and value. Each record is prefixed with a header that includes metadata such as the record's offset, size, and checksum.
Here's an in-depth explanation👇
Thank you for reading this edition of the newsletter!





