



Unleashing the Potential of Large Language Models (LLMs) with ChatGPT
Empowering Language Processing and Communication with Cutting-Edge AI Technology

In the realm of Natural Language Processing (NLP), Large Language Models (LLMs) have emerged as a powerful class of machine learning models. These models, including ChatGPT, have revolutionized language processing by digesting vast amounts of textual data and deciphering the intricate relationships between words. With recent advancements in computational power, LLMs have witnessed significant growth and enhanced capabilities. The size of their input datasets and parameter space plays a pivotal role in expanding their prowess.
The fundamental training approach for language models involves predicting the next word in a sequence. This can be observed through two common techniques: next-token prediction and masked language modeling.
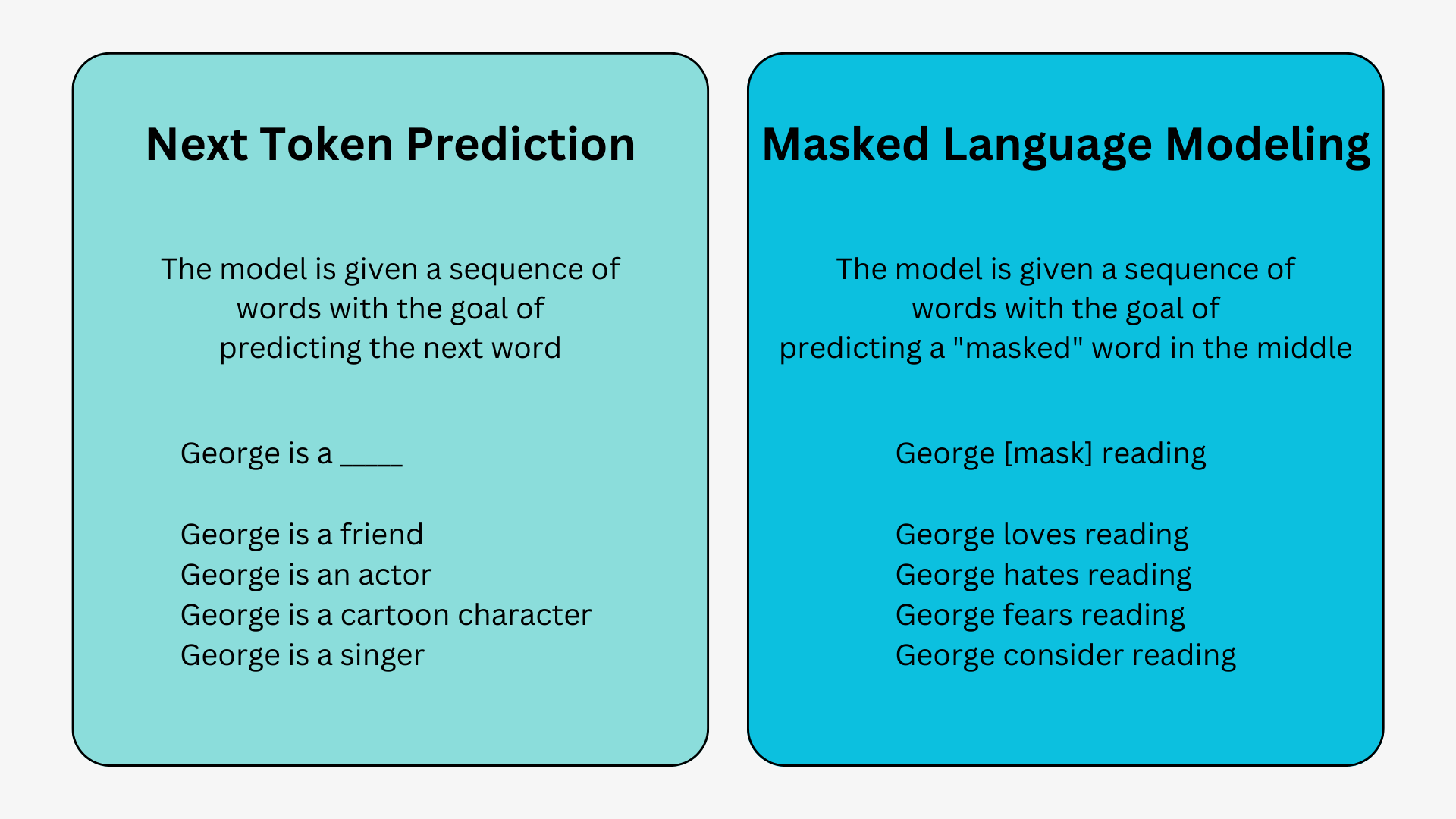
In these sequential modeling techniques, often implemented using Long-Short-Term-Memory (LSTM) models, the model fills in the missing word based on statistical probabilities and contextual cues from the surrounding text. However, there are notable limitations associated with this sequential modeling structure.
Firstly, the model lacks the ability to assign different values to surrounding words based on their relative importance. For instance, consider the phrase "George hates reading." While "reading" may commonly associate with "hates," there may be additional contextual information, such as George's passion for reading, which suggests that "love" would be a more suitable choice. The model's inability to prioritize certain words can lead to less accurate predictions.
Secondly, LSTM models process input data individually and sequentially, rather than considering the entire corpus as a whole. This means that the contextual window extends only a few steps beyond an individual input, limiting the model's ability to capture complex word relationships and derive nuanced meanings.
In response to these limitations, a breakthrough occurred in 2017 when transformers were introduced. Unlike LSTM models, transformers have the remarkable capability to process all input data simultaneously. By employing a self-attention mechanism, transformers assign varying weights to different parts of the input data relative to any position in the language sequence. This revolutionary feature has paved the way for substantial improvements in infusing meaning into LLMs and has enabled the processing of significantly larger datasets.
In 2018, openAI introduced the ground-breaking Generative Pre-training Transformer (GPT) models with the launch of GPT-1. Since then, these models have undergone remarkable advancements, evolving into GPT-2 in 2019, GPT-3 in 2020, and the most recent iterations, InstructGPT and ChatGPT, in 2022. Throughout their evolution, GPT models have witnessed significant progress driven by computational efficiency, enabling GPT-3 to be trained on vast amounts of data, leading to a more diverse knowledge base and expanded capabilities across a wide range of tasks.
At the core of all GPT models lies the transformer architecture, comprising an encoder for processing input sequences and a decoder for generating output sequences. Both the encoder and decoder incorporate a multi-head self-attention mechanism, allowing the models to assign varying weights to different parts of the sequence, thus inferring meaning and context. Additionally, the encoder employs masked-language modeling to understand word relationships and generate coherent responses.
The self-attention mechanism, a fundamental component of GPT's functioning, operates by converting tokens (textual elements such as words, sentences, or other groupings of text) into vectors that represent their significance within the input sequence.
As GPT models continue to evolve, researchers and developers are exploring further advancements, continually expanding their capabilities and refining their performance.





